專案作品
以下是我的專案,點擊卡片查看詳細資訊。
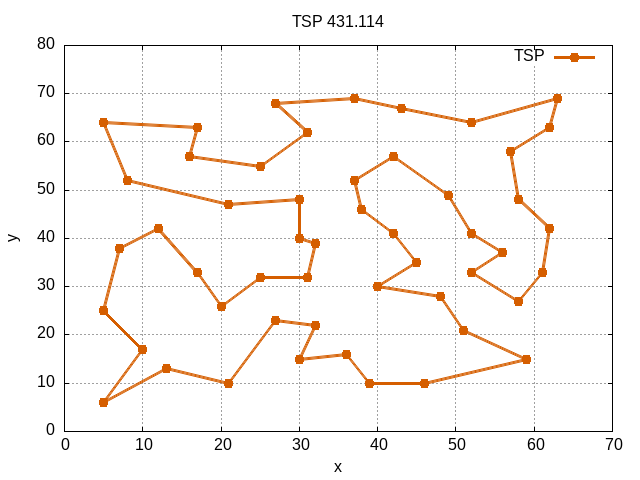
TSP : 旅行銷售員問題
使用 C++ 物件導向開發的後端服務,將該程式容器化並部署於 Google Cloud Run, 使用者可在 Demo 中輸入演算法參數,系統將生成蟻群演算法的最佳解並以視覺化方式呈現路徑。

使用 Verilog 對圖片進行卷積運算
Verilog 模擬電路的卷積運算,EDA tool 合成RTL設計並使用 testbench 驗證電路邏輯之正確性。 使用測量工具驗證時序邏輯、Critical Path和合成面積等。
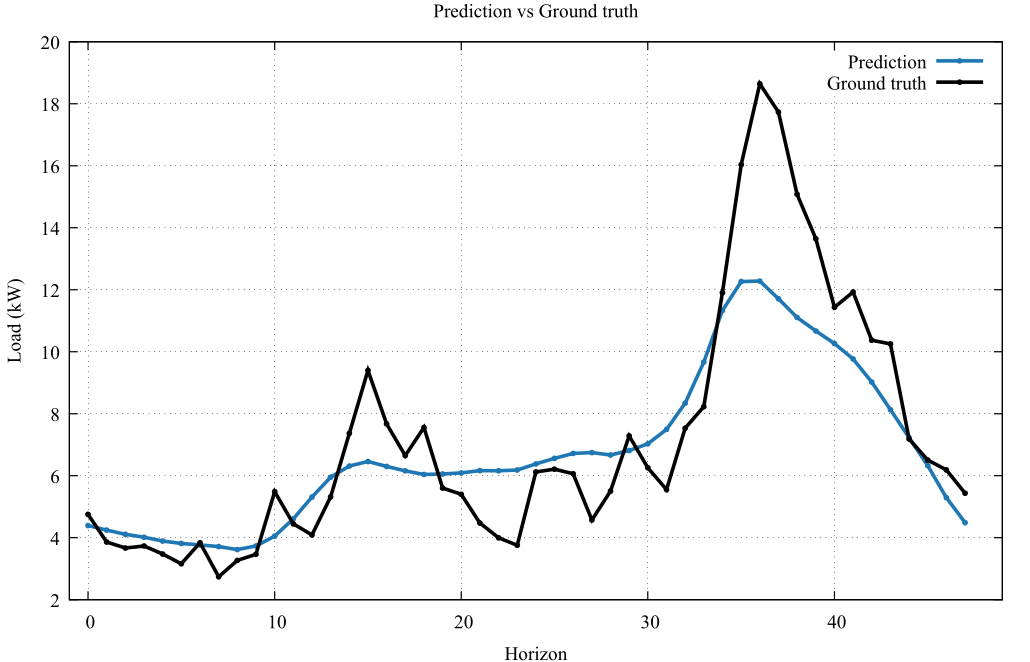
深度學習進行用電量預測
使用三種深度學習模型:Transformer, LSTM 和 TCN 對用電時序資料進行學習,針對不同的預測場景, 採用不同模型輸出模式,提高用電量預測的準確度。
專案成果
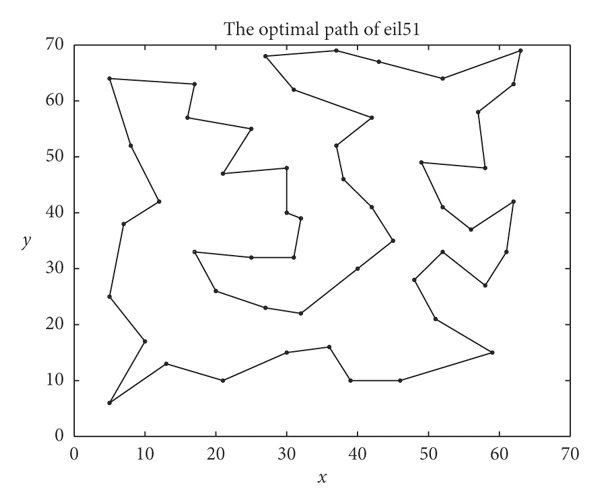
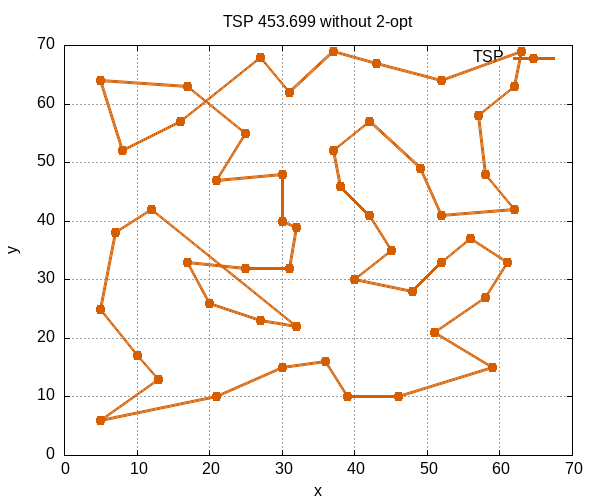
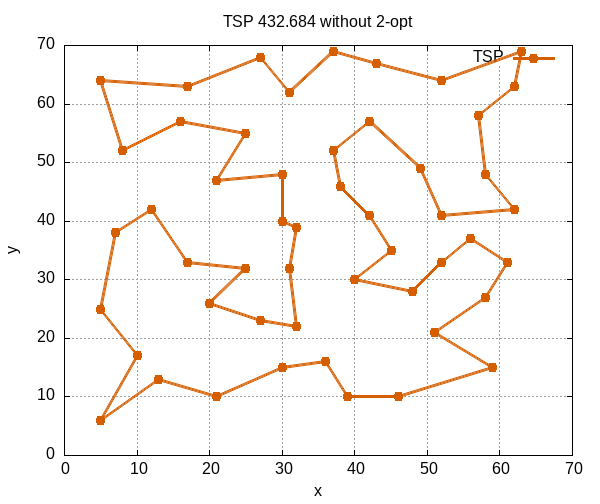
此處展示三張圖,基於 eil51 資料集,第一張圖是此資料集之最短路徑。 第二張圖展示使用蟻群演算法但未經 2-opt 優化所生成之路徑,圖中可見路徑存在交叉,這些交叉路徑會增加總長度。 第三張圖展示採用 2-opt 技術消除交叉路徑後的結果,路徑長度得到進一步縮短。
專案成果






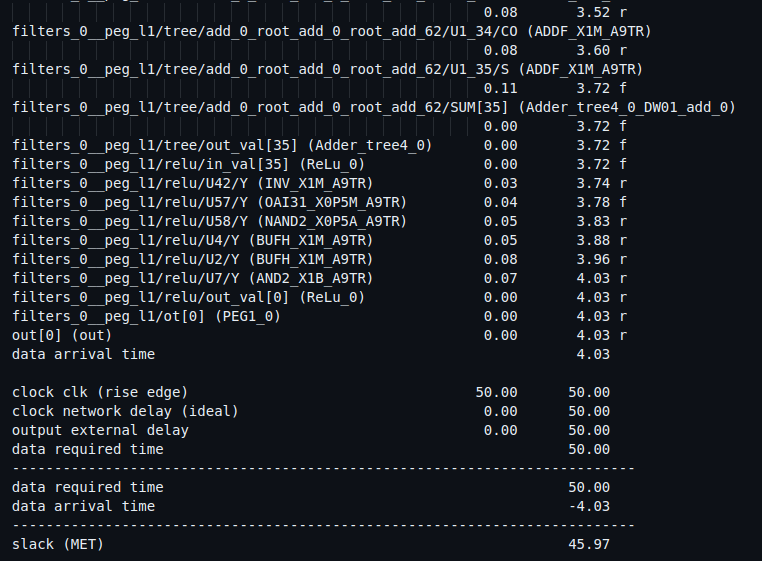
上面展示一張原始的貓咪圖片(左邊)以及經過五個來自 CNN 內部 kernel 處理後的 feature map(右邊)。 這些 kernel 提取了不同的圖片特徵,例如貓咪的輪廓或背後的草 。 在合成階段使用 TSMC 設計工藝庫進行映射,並透過 Synopsys PrimeTime 進行時序分析, 在 20 MHz 時鐘頻率(50 ns 週期)下,critical path 延遲為 4.03 ns。
技術細節
- 使用 ISET 和 Ausgrid 資料集驗證模型推理能力,對資料集進行時間序列分解與缺失值填補。
- 使用 Python 和 PyTorch 搭建深度學習模型,實現 BiLSTM、TCN 和 Transformer 等子模型,捕捉時間序列中的短期與長期模式。
- 採用 stacking 集成學習框架,設計元學習器整合子模型預測結果,從實驗結果可看出,元學習器可有效整合個子模型之優勢,使預測準確度更進一步提昇。
- 針對不同的預測場景,採用不同的 Transformer 推理方式。在短步長輸出的情況下,使用 generative 推理方式,能夠捕捉更長的歷史數據依賴;在多步長的情況下,使用 autoregressive 推理方式,將預測值作為下一個時間點的輸入,迭代此過程直至完成整個預測。
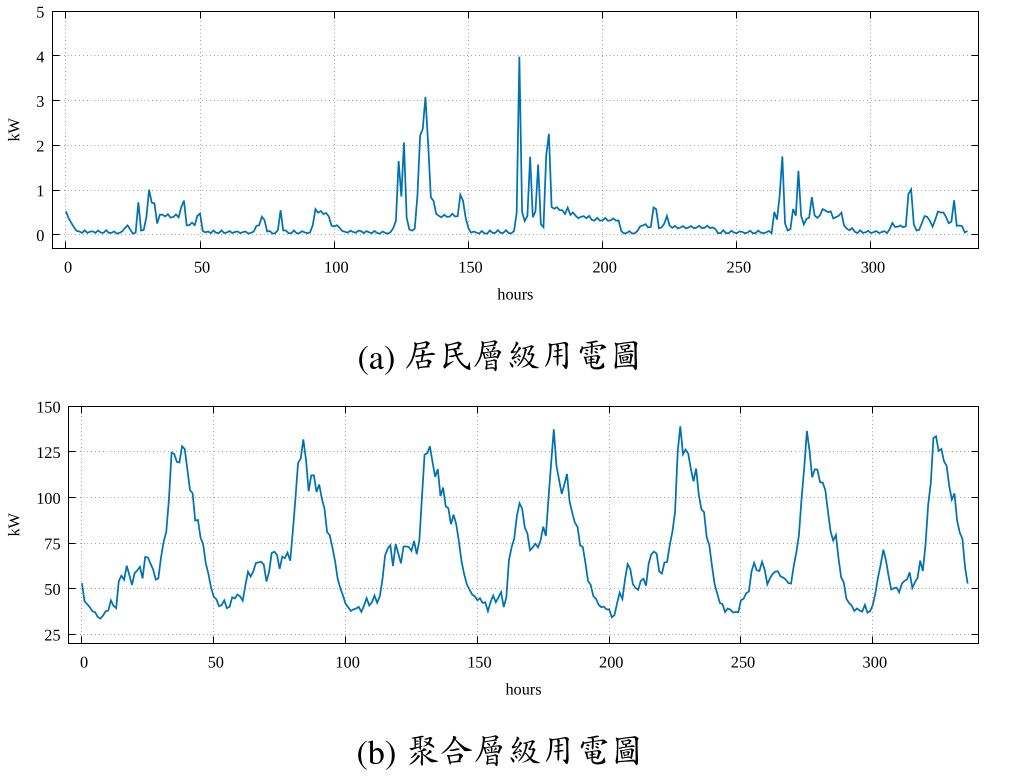
此圖展示了不同層級的用電模式,包括聚合層級(aggregated level)與居民層級(residential level)的用電量變化趨勢。
聚合層級數據反映了整體電網的用電情況,呈現出較為平穩的波動,
而居民層級數據則顯示出較明顯的日間尖峰與夜間低谷,反映了單戶家庭用電行為的特性。
居民層級上,用電量通常只有於 0 瓩 (kW) 附近變化,且用電曲線存在許多呈九十度
向上的尖峰用電,這是因如果開啟高耗能的電器如冷氣或烤箱等,用戶用電量會一下
子從谷底就被拉升頂峰。如左圖 (a) 中的第 170 時間點附近,用電量突然從 0 瓩飆升至 4 瓩,
且接著為連續高低震盪的用電行為。相較之下,聚合層級的用電曲線就顯得
較有規律性,如左圖 (b) 中的用電行為約為 48 個時間點為一個週期,且曲線中的尖 峰不再像居民層級那麼銳利。
這一分析有助於理解不同場景下用電需求的差異,為後續模型設計提供了重要依據。
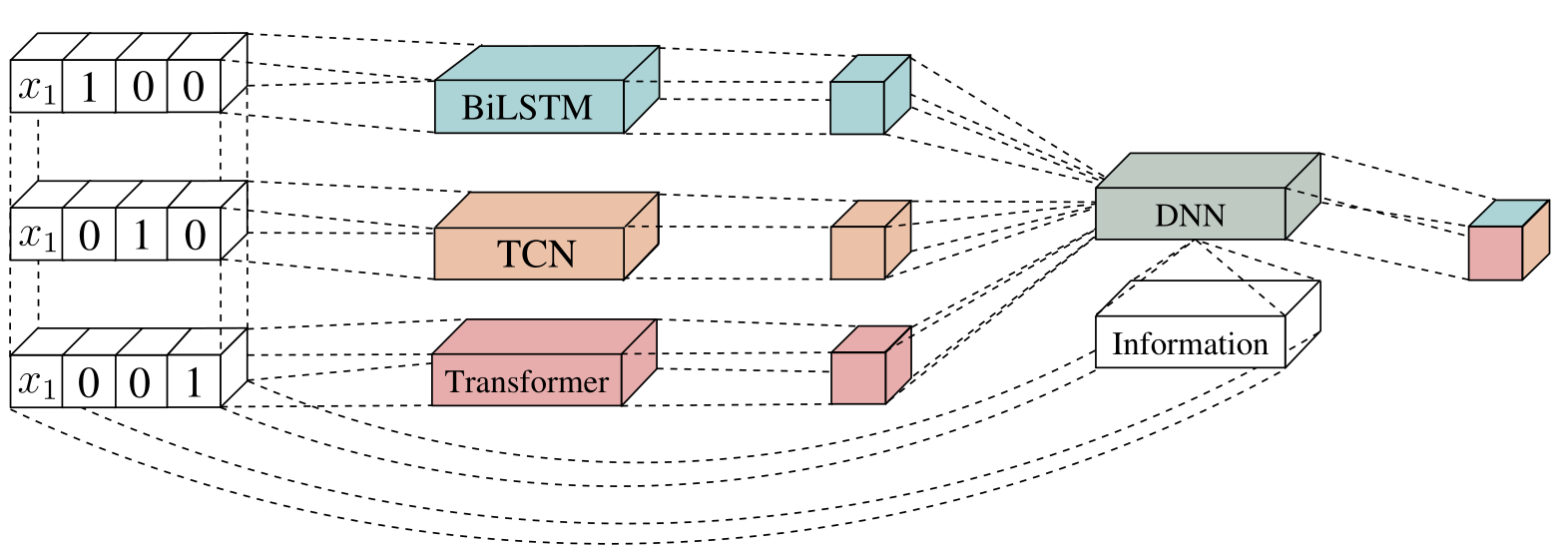
居民層級元學習器設計
此圖呈現了元學習器在 stacking 框架下的整合架構。
該架構包含多個子模型,包括 BiLSTM(雙向長短期記憶網路)、TCN(時間卷積網路)和 Transformer,
分別負責捕捉時間序列中的短期依賴、長期趨勢和全局特徵。子模型的輸出結果被傳遞至元學習器,
與簡單平均不同,元學習器會動態調整各子模型的權重,根據它們的預測表現優化最終結果。
圖中虛線部分顯示,元學習器還會考慮用電曲線變化和用戶資訊。
透過一維卷積網路提取用戶特徵,並將其與子模型預測結合,元學習器能更精準地為每個用戶調整權重,進一步降低預測誤差。
這種設計讓模型能適應不同用戶的用電模式。
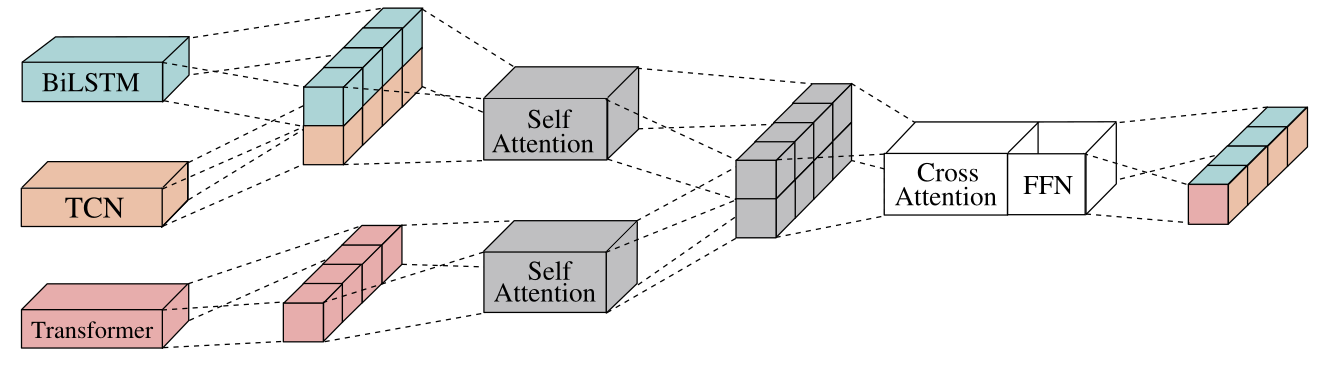
聚合層級元學習器設計
不同於居民層級的設計,右圖呈現了聚合層級的元學習器設計,目標是預測未來一段時間的總用電量。
元學習器主要由多個自注意力(Self-Attention)運算組成,處理來自 BILSTM、TCN 和 Transformer 的時間序列預測。
為保留序列順序資訊,模型先將 BILSTM 和 TCN 的預測拼接並進行位置編碼,再通過多頭自注意力運算,生成第一特徵序列。
Transformer 的預測同樣經過位置編碼和自注意力運算,生成第二特徵序列。
模型以第二特徵序列作為查詢向量,將第一特徵序列映射後作為鍵(key)和值(value)向量,再次進行自注意力運算。
這種設計利用 Transformer 的預測序列挖掘其他模型預測間的關聯性,相較於直接攤平序列輸出,能更深入分析序列交互,提升最終預測的精準度。
專案成果
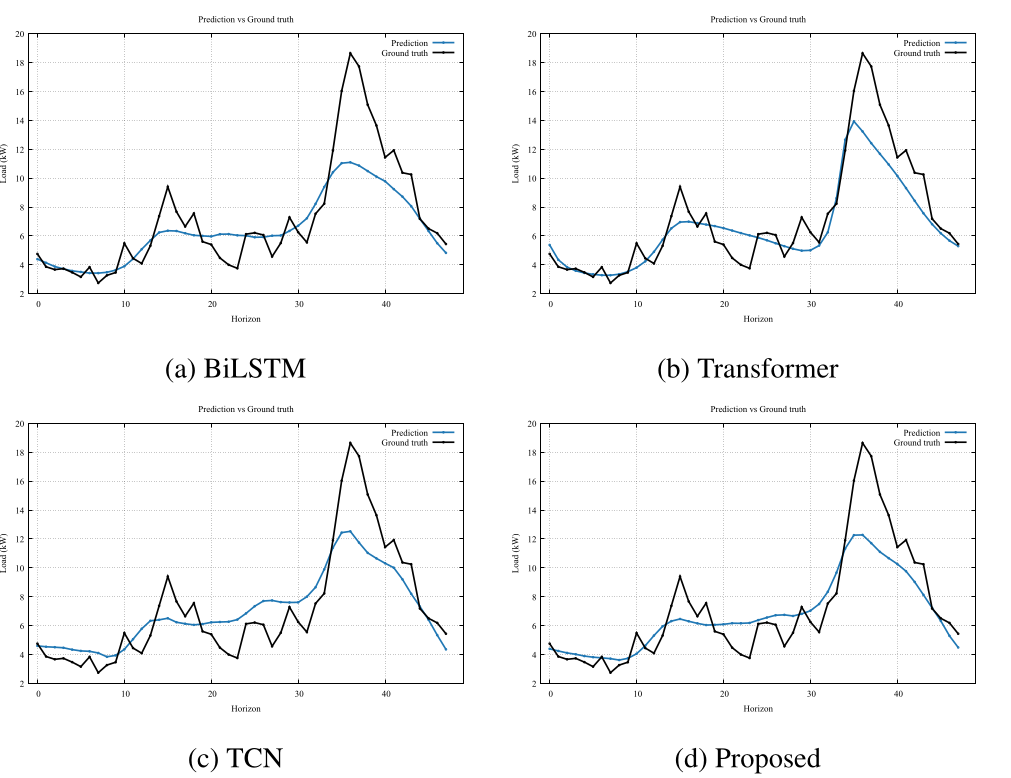
此圖比較了模型預測值與真實值在 Ausgird 數據集上的表現,挑選四個不同預測長度的範圍,測試不同模型面對同一段輸入所做出的預測結果。較長預測 長度對於模型是較為困難的,因在既有的資訊較有限的情況之下做出長時間的推測是 較為複雜的一項任務,考驗模型對於序列的歷史序列的理解與對未來序列分析的能力。 圖中展示了 BiLSTM、TCN 和 Transformer 三個子模型的預測結果,以及最終 stacking 模型的預測曲線與真實用電量的對比。 結果顯示,看到對於較短的預測長度時,模型能夠較好的貼近其實際值,隨著預測的範圍加長時, 預測的難度逐漸提升。當模型在預測 32 至 36 時間點時,Transformer 模型展現了極佳的預測效果,其預測值與實際值具有高度的重疊性。 所有模型在預測較遠未來時間點時,對尖峰的捕捉能力皆有待進一步提升。
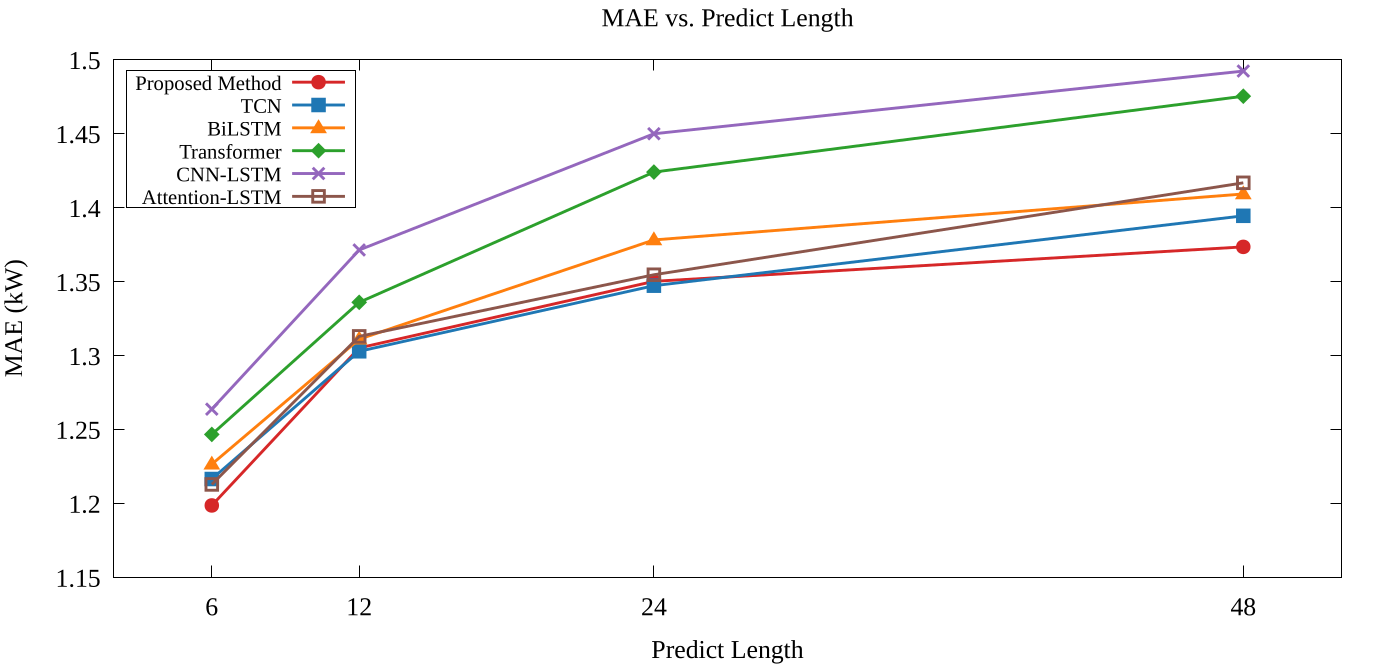
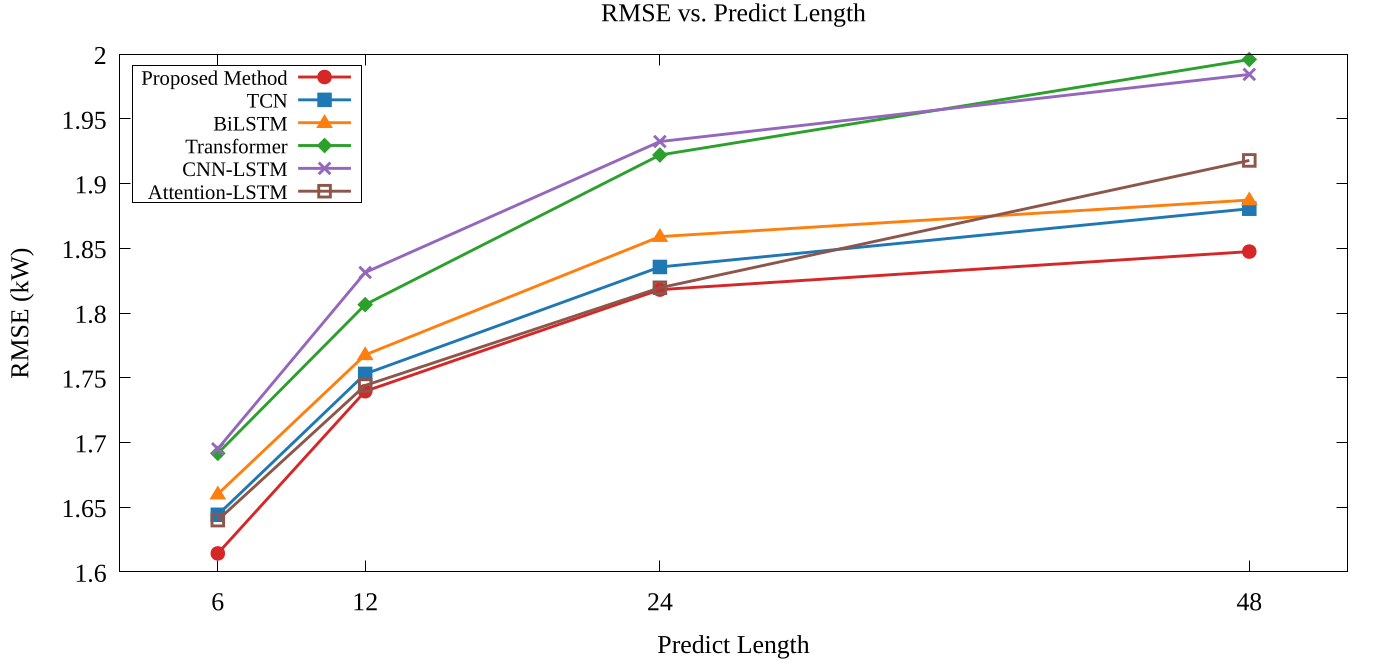
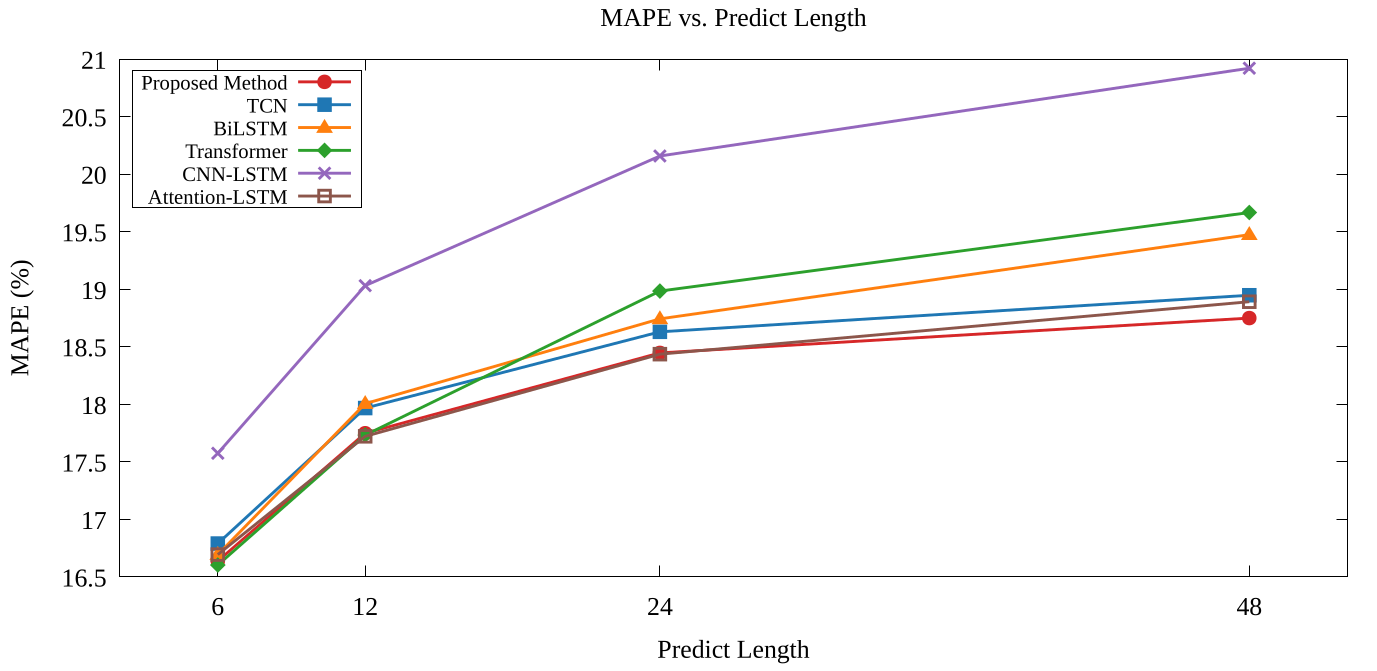
此圖展示了所提出的方法(Proposed method)與其他模型在不同預測長度(Predict Length)下的表現,評估指標包括 MAE、RMSE 和 MAPE。 圖表中的模型涵蓋 BiLSTM、TCN、Transformer、CNN-LSTM、Attention LSTM 以及所提出的方法, 其輸入資料來自 Ausgrid 數據集的聚合層級(aggregated level)。可觀察隨著預測長度從 6 增加至 48,MAE、RMSE 和 MAPE 均呈現上升趨勢, 反映了長時序預測的挑戰性。 而所提出的方法在預測長度較長的場景下各指標均保持較低的誤差。 以上圖(左)為例說明,所提出的方法在預測長度為 48 時,MAE 約為 1.35,RMSE 約為 1.82, MAPE 約為 18.5%,皆優於其他的比較模型。 可看到即便子模型在預測長度較長的情況下,指標的表現可能並不出色,透過元學習器的整合,可以有效的使預測誤差進一步的減少。 這些結果顯示,透過 stacking 集成學習整合多個子模型,能有效提升用電量預測的精準度, 尤其在長時序預測場景中表現更為突出。
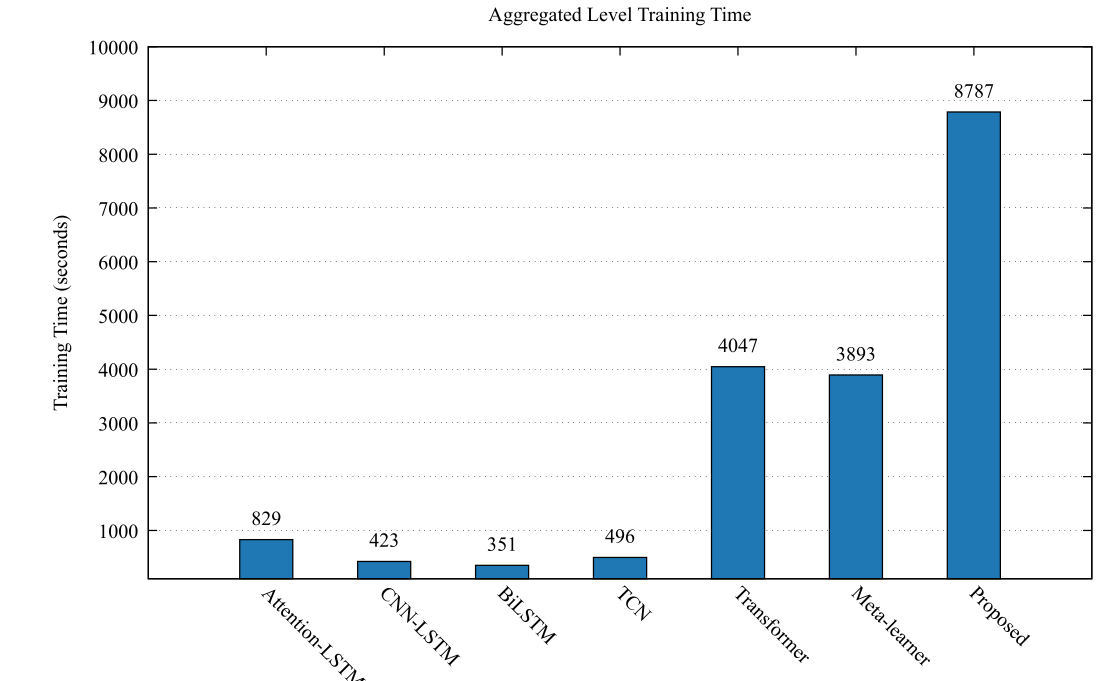
此圖展示了不同模型在訓練過程中的時間消耗比較, 圖中包括 BiLSTM、TCN、Transformer 和所提出的 stacking 模型在相同硬體環境下的訓練時長。 可以看到 BiLSTM 模型的訓練時間最短,僅為 351 秒。 CNN-LSTM 和 Attention-LSTM 模型分別需要 423 秒和 829 秒,transformer 和元學習器則顯示出較高的訓練時間需求,其原因為自注意力計算的方式具有較高的時間複雜度,故須額外花費較多的運算成本。 雖然 stacking 模型由於整合多個子模型,訓練時間相對較長,但其整體時間消耗仍控制在合理範圍內。 結合模型在預測精準度上的提升,該方法的計算成本認為是可接受的,特別是在需要較高精準度的預測應用場景中。
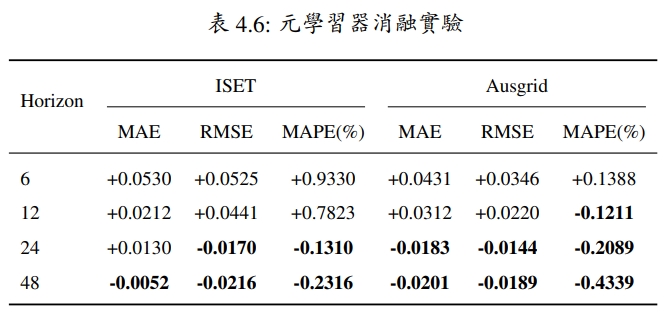
在右表將以一般未加入自注意力機制之元學習器作為基準。 其因各項評估指標為越小值表示預測性能較好,故在表中以負值呈現為擁有較優異之表現。 可從表中發現,不管是在面對多變數資料集或單變數資料集, 在預測較長範圍的時間步長時,在元學習器中加入自注意力機制可有效減小預測誤差。且當預測範圍愈加長時,自注意力機制可有效降低長時間的預測誤差。但當預測範圍 較短時,自注意力機制則會造成模型過度複雜,導致所預測之誤差無法有效的降低。